让我们来看一下我们刚刚生成的DBC 数据库。我们从Python书写内容开始:
import textwrap
from canlib import kvadblib
with kvadblib .Dbc( filename=’db_histogram . dbc ’ ) as db:
print (db)
for message in db:
print ( ’\n {} ’ . format(message) )
for signal in message :
print (textwrap . f i l l ( ’ {} ’ . format( signal ) , 80))
使用textwrap模块来生成一个简洁的80字宽输出:
Dbc db_histogram: flags:0, protocol:CAN, messages:4
Message(name=’LIM_002’, id=402, flags=<MessageFlag.0: 0>, dlc=8, comment=’’)
Signal(name=’Load’, type=<SignalType.FLOAT: 3>,
byte_order=<SignalByteOrder.INTEL: 0>, mode=-1, size=ValueSize(startbit=0,
length=32), scaling=ValueScaling(factor=1.0, offset=0.0),
limits=ValueLimits(min=0.0, max=100.0), unit=’metric ton’, comment=’Measured
load in system.’)
Message(name=’ECM_004’, id=504, flags=<MessageFlag.0: 0>, dlc=8, comment=’’)
Signal(name=’Fuel’, type=<SignalType.FLOAT: 3>,
byte_order=<SignalByteOrder.INTEL: 0>, mode=-1, size=ValueSize(startbit=0,
length=32), scaling=ValueScaling(factor=1.0, offset=0.0),
limits=ValueLimits(min=0.0, max=300.0), unit=’l/100 km’, comment=’Current fuel
consumption.’)
Message(name=’ECM_003’, id=503, flags=<MessageFlag.0: 0>, dlc=8, comment=’’)
Signal(name=’EngineTemp’, type=<SignalType.FLOAT: 3>,
byte_order=<SignalByteOrder.INTEL: 0>, mode=-1, size=ValueSize(startbit=0,
length=32), scaling=ValueScaling(factor=1.0, offset=0.0),
limits=ValueLimits(min=-60.0, max=200.0), unit=’Celsius’, comment=’System
temperature consumption.’)
Message(name=’ECM_001’, id=501, flags=<MessageFlag.0: 0>, dlc=8, comment=’’)
Signal(name=’EngineSpeed’, type=<SignalType.UNSIGNED: 2>,
byte_order=<SignalByteOrder.INTEL: 0>, mode=-1, size=ValueSize(startbit=0,
length=32), scaling=ValueScaling(factor=1.0, offset=0.0),
limits=ValueLimits(min=0.0, max=6000.0), unit=’rpm’, comment=’Current engine
speed.’)
希望这里不要有什么不正常,所以让我们看一下我们的数据库在Kvaser 数据库编辑器里是怎么样。
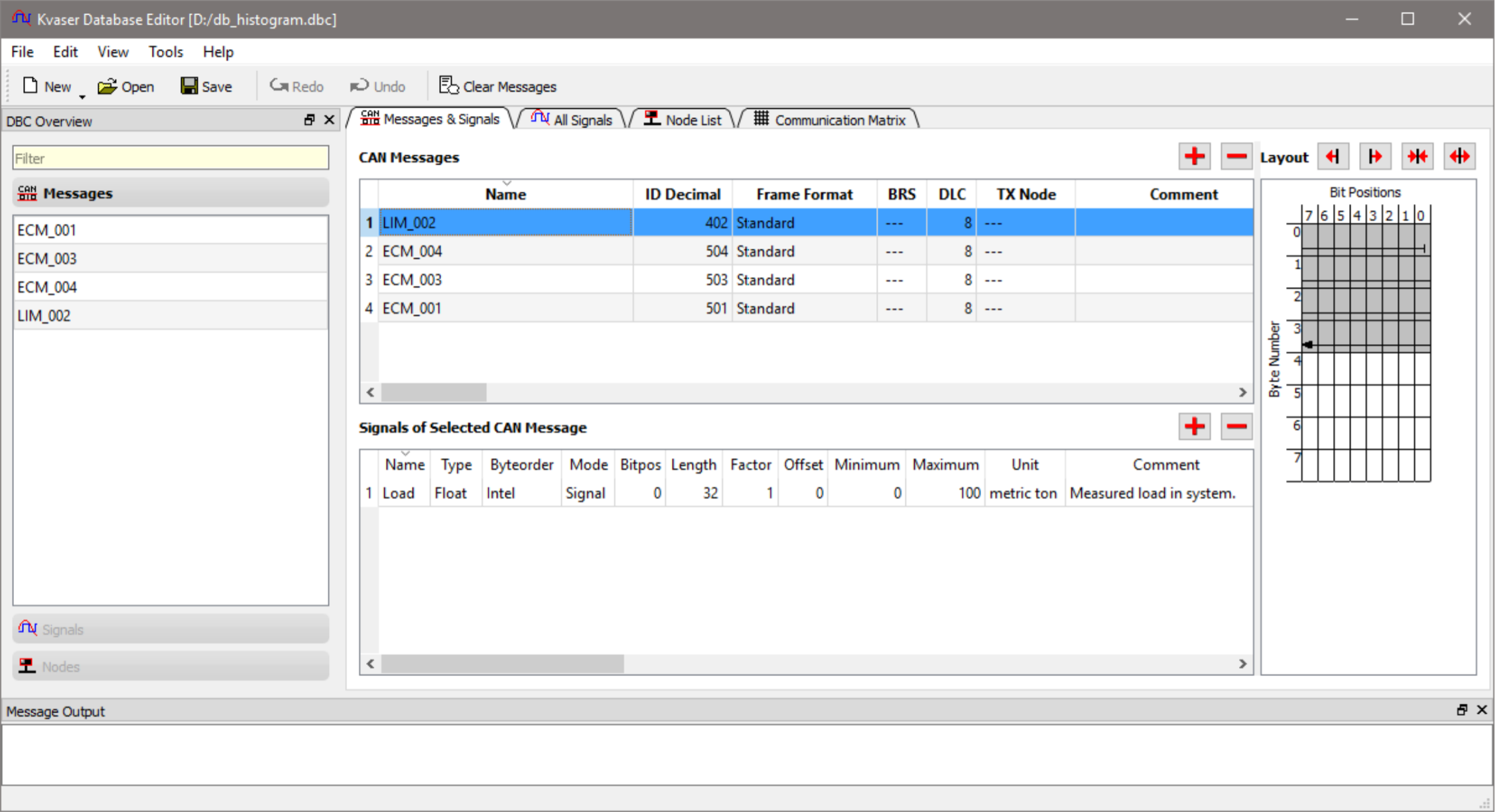
图1:在Kvaser 数据库编辑器里看我们的数据库。
在Kvaser数据库编辑器的中间框里,我们能看到4个已定义的报文。在图1中1, 报文“LIM_002”被选择,该报文的内容显示在此报文下面。在我们的例子里,有一个名为“Load”的信号,它的单位unit被设为“metric ton”。在右边的方框中,当前报文的数据bits以一个布局(有阴影的格子)显示。 在图中 1, 我们能看到被选中的信号是从第一个byte 的bit 0 到第三个byte的bit 7, 这和开始位置0和给出的长度32相对应。
这样我们就结束了此博客的第一部分,介绍怎样生成一个数据库。在下一个部分我们将看一下在发送和接收信号时怎样使用数据。